kcp是一个实现了类似tcp的重传、流控、拥塞控制等机制的传输协议,它没有指定传输协议,但是一般情况下都会用udp来传输,
相当于用udp实现的tcp协议。它在不稳定的网络环境中采用更激进的方法来获得比tcp更快的传输速度,代价就是会消耗更多的流量。
跟tcp一样,kcp采用滑动窗口机制来实现流控,通过重传机制保证了可靠性,通过慢启动,拥塞避免,快速重传和快速恢复来实现拥塞控制。
kcp支持两种模式:流模式和消息模式。
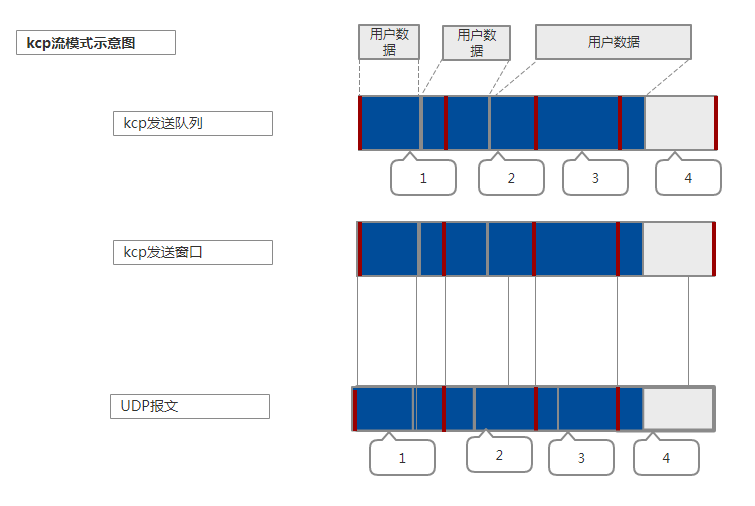
流模式具有更高网络利用率,更大的传输速度,但是解析数据相对更复杂。
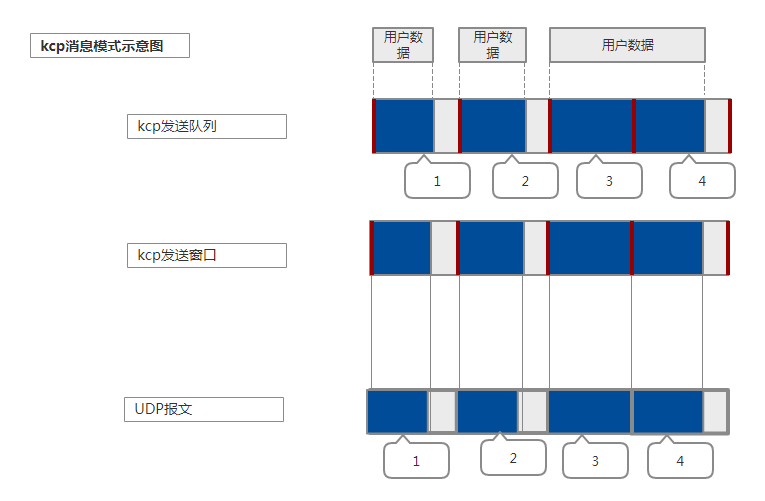
消息模式具有更小的网络利用率,更小的传输速度,但解析数据更简单。
相关变量
| 字段 | 含义 | 注释 |
|---|---|---|
| rcv_wnd | receive window | 接收窗口大小 |
| rmt_wnd | remote window | 远端可接收窗口。发送端发送数据的时候带上,接收端接收到数据时更新(input的时候更新) |
| snd_wnd | send window | 发送窗口大小,默认 32,静态值。用于计算 cwnd |
| cwnd | congestion window | 拥塞窗口大小,会根据丢包或者ack调整,cwnd=min(snd_wnd,rmt_wnd),只有 nc==0 的时候才会更新并使用这个值 |
| rcv_buf | receive buffer | 接收缓冲区,缓冲底层接收的数据,组装连续以后拷贝到接收队列 |
| rcv_queue | receive queue | 接收队列,接收的连续数据包,上层应用可以直接使用,不能超过接收窗口大小 |
| snd_queue | send queue | 发送队列,上层应用数据分片后加入发送队列,发送队列的数据不会立即发送,头部还没有完成初始化 |
| snd_buf | send buffer | 发送缓冲区,已发送尚未确认的包 |
| buffer | 调用output发送的数据 | |
| probe | ICKP_CMD_WASK IKCP_CMD_WINS | |
| acklist | sn,ts | 待发送的ack列表 |
| fastresend | 快速重传门限,无须等待超时,如果n没收到ack但是收到了n+1,n+2,…n+fastresend那么立即重传n | |
| ssthresh | slow start thresh | 慢启动拥塞窗口阈值,不小于2 |
| incr | 可发送的最大数据量,incr=cwnd*mss,因为拥塞避免阶段cwnd的增加不足一个包,所以需要维护这么个变量,当满了一个mss以后给cwnd自增 | |
| stream | stream mode | 是否使用流模式 |
| mss | max segment size | 最大报文长度,mtu - (24 头部长度) |
| mtu | max transfer unit | 默认1400,不小于50 |
RTO计算(Retransmission timeout)
kcp的重传超时计算方法参考了tcp的实现Computing TCP’s Retransmission Timer,不过在参数设置上更加激进。
计算过程主要维护两个变量:
- SRTT: smoothed round-trip time
- RTTVAR: round-trip time variation
接收端收到确认包以后根据rtt更新这两个变量,并重新计算rto值。报文超时以后tcp的rto会翻倍,
kcp中声称采用的是1.5倍,然而代码中实际上是线性增加,不知道是作者有意为之还是实现bug。
Segment头部
| 含义 | 会话id | 包类型 | 是否分片 | 发送端接收窗口 | 时间戳 | 包序列号 | 未确认包序号 | 数据长度 | 数据 |
|---|---|---|---|---|---|---|---|---|---|
| 字节数 | 4 | 1 | 1 | 2 | 4 | 4 | 4 | 4 | len |
| 字段名 | conv | cmd | frg | wnd | ts | sn | una | len | data |
| 全名 | conversation id | command | fragment | window | timestamp | segment number | unacknowledge | length | data |
报文字段含义:
| 字段名 | 含义 |
|---|---|
| conv | 通信双方需要保证相同的会话id |
| cmd | ICKP_CMD_PUSH/IKCP_CMD_ACK/IKCP_CMD_WASK/ICKP_CMD_WINS |
| frg | 分片ID,从大到小,0表示最后一个分片 |
| wnd | 剩余接收窗口大小(接收窗口大小 - 接收队列大小) |
| ts | message发送时刻的时间戳 |
| sn | 分片segment序号 |
| una | 待接收消息序号(接收滑动窗口左端) |
| len | 数据长度 |
| data | 数据 |
| fastack | 收到ack时计算的该分片被跳过的累积次数 |
| xmit | 分片发送的次数,每发送一次加1,超出dead_link,说明目标不可达 |
| resendts | 下一次超时重传的时间戳 |
| rto | 该分片的超时重传等待时间 |
API
kcp与底层交互
1 | int ikcp_output(ikcpb *kcp, const void *data, int size) |
这两个结构是kcp与底层网络交互的接口。一般底层网络指的是UDP。
output将kcp打包的数据发往目的地址,而input是底层网卡收到udp数据以后喂给kcp层。
底层收到数据报文后调用input,将数据丢给kcp。
上层通过recv获得处理后的数据,循环从data中取出kcp包。直到剩下的长度小于包头长度退出循环。
input传入的数据包含kcp包头,kcp拿到以后会尝试去掉kcp包头,组合成一个完整的数据包:
- 长度小于包头长度24,退出循环。
- 构造包头,分别检查会话id,数据长度,包体类型。
- 设置远程剩余接收窗口大小。
- 将对方已经确认收到的包从发送缓存snd_buf中删除,相当于发送窗口右移。
- 计算本地真实snd_una,也就是下一个等待确认的发送包。
- 如果还有未确认的包,为发送窗口左端包序列号
- 如果没有未确认包,即发送窗口为空,则为下一个发送包snd_nxt
- 根据包的不同类型分别处理
- ACK包:
- 计算rtt,更新rto,更新算法参考rfc6298
- 从发送窗口中删除对应的包,并更新此包之前未确认包的fastack信息
- PUSH数据包:
- 判断收到的包的sn是不是位于区间:[rcv_nxt, rcv_nxt+rcv_wnd), 是则继续,否则丢弃
- 在接收窗口内,将其加入acklist,下一次flush的时候确认
- 构造一个kcp包,判断是否重复,如果不是重复包,插入接收缓存rcv_buf中对应位置
- 将rcv_buf中的已经收到的连续包移到接收队列rcv_queue中,供上层应用读取,并从rcv_buf中移除
- WASK包:
- 设置probe的TELL标记,flush的时候推送
- WINS包:
- 无须处理,因为之前已经设置了对方的剩余接收窗口大小
- ACK包:
所有包处理完毕以后,根据对方确认包的信息,更新拥塞窗口大小。
- 如果拥塞窗口小于对方剩余接收窗口,则需要更新
- 如果拥塞窗口尚未达到ssthresh(慢启动门限),cwnd++
- 如果大于ssthresh,
kcp与应用层交互
1 | int ikcp_recv(ikcpcb *kcp, char *buffer, int len) |
- 将接收队列中的消息传递给上层应用,因为消息会被拆分成kcp包,所以消息长度需小于接收队列长度*报文长度。
- 将接收缓冲中的连续报文拷贝到接收队列。
- 如果接收队列从满到不满,推送窗口通知消息给发送端,通知有接收窗口,可以继续发送新的报文。
- ikcp_recv返回大于0的数的时候,buffer里面必然是一个完整的包。所谓完整的包,也就是对应发送方调用ikcp_send的时候发送的buffer。应该是一一对应的。原本我以为如果发送的包需要分段,那么需要把长度加到buffer前面,其实是没有必要的。因为peeksize就保证了,必须是一个完整的包才会返回大于0的数。
- stream=0的话可以保证收到的是一个 send时传过去的完整的包。流模式和包模式的问题
1 | int ikcp_peeksize(const ikcpcb *kcp) |
检查接收队列中是否有一个完整的消息,并返回消息的长度。
1 | int ickp_send(ikcpcb *kcp, const char *buffer, int len) |
发送应用层的数据,会根据mtu大小分片,每个分片加上segment头部24字节,加入发送队列snd_queue。
根据stream字段区分流模式和消息模式。不同模式组包的机制不一样。如果是消息模式,分片数据的frg字段从count-1到0,0表示分片结束。发送的数据最大不能超过 128 * mss 大小。kcp-go 为了突破这个限制,在应用层对包的大小进行了切分,每次只发一个mss,这样就调用 write 的时候就可以发送很大的数据。为什么有这个限制呢,这是因为 kcp 支持包模式,包模式依赖一个 frg 来组装大包,这个id 在 kcp 头部占用的字节就是一个。
1 | void ikcp_update(ikcpcb *kcp, IUINT32 current) |
根据传入的时钟,决定是否调用flush。kcp维护一个ts_flush表示下一次flush的时间,update的时候如果发现当前时间已经大于等于ts_flush,则执行flush。
1 | int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc) |
配置参数。interval的范围是10ms到5000ms。默认是100ms。interval决定了实际调用flush的频率。
nc 0: normal congestion control(default), 1: disable congestion control 。这个值控制 kcp 是否进行拥塞控制。
nc 表示 nocwnd,表示是否尊重拥塞控制。默认是 0,会尊重拥塞控制,在发生丢包或者重复确认的时候减小拥塞窗口。
如果配置为 1 ,则表示不遵守拥塞控制。所以默认情况下 kcp 也可以像 tcp 那样遵守公共规则,但是如果打开这个开关,
kcp 就不遵守公共规则,表现的比较自私。
cwnd 表示可以 inflight 的包的数量,这个值越大,kcp 发包越多。类似于压测工具的 pipeline 参数。能够 pending 的包的个数。这个参数收到两个参数的严格控制,一个是自己的发送窗口,一个是对端的接收窗口。如果考虑到拥塞控制,还应该受到拥塞窗口的控制。kcp 通过 nc 选项来决定是不是遵守拥塞控制规则,即ss,cc,fastack,fast recovery等拥塞控制计算出来的拥塞窗口。
kcp 会将 cwnd 个数的包挂在 snd_buf 队列中。
1 | void ikcp_flush(ikcp *kcp) |
实际发送数据的接口。
- 发送acklist中的ack消息
- 如果对方接收窗口为0,需要发送IKCP_CMD_WASK消息,检查probe对方接收窗口是否ready
- 发送自己的接收窗口大小
- 发送数据
snd_buf 是一个带 sentinel 的循环链表。
ikcp_parse_una 接收端接收到数据包,解析出对端尚未确认的包,那么小于una的说明都已经确认,如果发送缓冲中还在,直接删除。
同时,由于接收端接收到了新的数据,所以需要更新自己的 send_una 也就是尚未确认收到的包。如果发送缓冲中有包,那么就是发送缓冲中的第一个包的sn。
否则就是下一个需要发送的sn:kcp->snd_nxt。
kcp-go
go 版的 kcp ,会话有一个 writeDelay 的标识。表示有数据是是否立即发送,还是等到下一次 update 的时候发送。默认是不 delay,立刻发送。
当 waitsnd < snd_wnd 时,要发送的数据直接挂到 kcp 缓存中。然后再次检查 wait_snd 是否超过 snd_wnd ,如果是,则立刻 flush 。
所以有两种情况下,Write 是立刻发送的:一个是 waitSnd 大于 snd_wnd ,另一个是会话的默认配置,不 delay。
rmt_wnd 每个包都会带上一个wnd,收到对面的wnd,就是rmt_wnd。
kcp.cwnd 不会超过 rmt_wnd。
如果 rmt_wnd 为0,表示对面已经没有能力接收。隔 7 秒发送一个 probe window size。每次1.5倍增加试探时间。最多增加到 120 秒。